OpenAI Whisper: Best guide to getting started with speech to text AI


OpenAI Whisper is a new Automatic Speech Recognization AI system.
Whisper is created by OpenAI, the company behind GPT-3, Codex, DALL-E, etc.
OpenAI Whisper can do automatic speech recognization and convert speech to text at high quality as well as can do very efficient non-English speech to English text with translation at very efficiently.
 Image Credit: OpenAI. Whisper Speech to text with translation
Image Credit: OpenAI. Whisper Speech to text with translation
Whisper’s code is available as Open Source and free for anyone to modify or use in their workflow or applications. It is now also available to be used from OpenAI’s No Code App called Playground as well as through API for building apps or writing programs.
In this article, we will go through a few of the easiest ways to use Whisper locally on your machine.
- Using OpenAI Whisper from OpenAI Playground GUI
- Using OpenAI Whisper via OpenAI API in code
- Install and use OpenAI whisper locally on your machine
This guide can be used on Mac, Windows, or a bunch of Linux flavors like Ubuntu, Debian, Arch Linux, etc.
Table of Contents
- Using OpenAI Whisper from OpenAI Playground GUI
- Using OpenAI Whisper via OpenAI API in code
- Installing OpenAI Whisper on your machine
- Using OpenAI Whisper
- Various OpenAI Whisper models
- OpenAI Whisper language support
Using OpenAI Whisper from OpenAI Playground GUI
- Login to OpenAI Playground
2. From the model drop-down on the left side of the page, choose audio-transcribe-001 (the model name for Whisper)
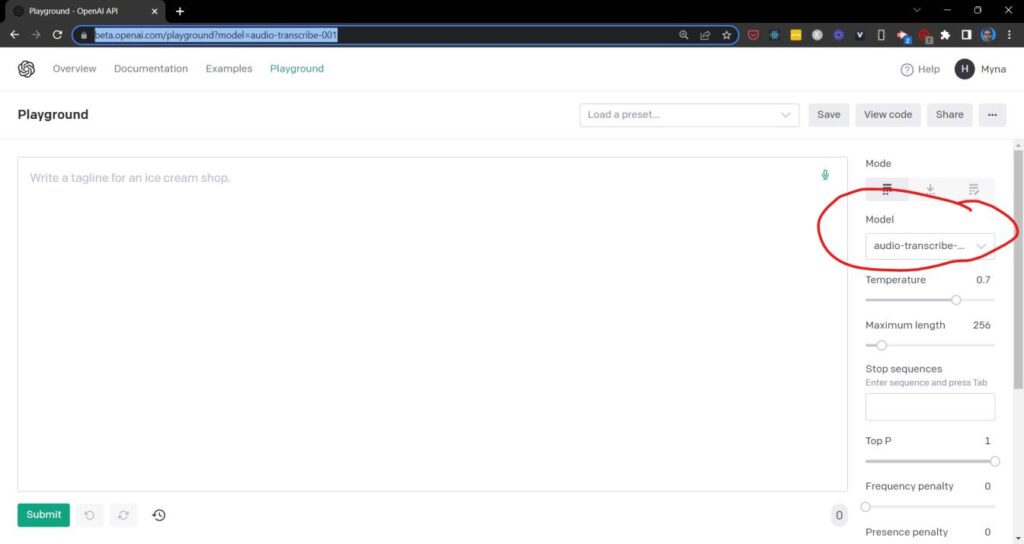 HarishGarg.com – OpenAI Whisper Playground
HarishGarg.com – OpenAI Whisper Playground
3. Click on the green microphone button. It will bring up the audio upload or record dialog
 OpenAI – PLayground – Whisper
OpenAI – PLayground – Whisper
In the above, you can choose to upload an audio file or record fresh audio.
4. Once done, the transcription will start automatically
 OpenAI Whisper in Playground
OpenAI Whisper in Playground
5. Once finished (it might take few mins depending on how large the audio file is), you will see the transcribed text in a popup
 openai-whisper-playground-api-results
openai-whisper-playground-api-results
6. You can copy and use this text wherever you want or you could click on Use as input which will pate it in the OpenAI Playground and you can use it as input to other OpenAI models, for example, summarizing it using GPT-3.
Using OpenAI Whisper via OpenAI API in code
 harishgarg.com – openai whisper API in playground
harishgarg.com – openai whisper API in playground
Installing OpenAI Whisper on your machine
Requirements
You should have Python 3.7 or higher installed on your computer.
Open the command line and run the command python -v or python3 -v to confirm this.
If you do not have Python 3.7 or higher, you should consider installing or upgrading Python before proceeding further.
Setup
Install ffmpeg
You need to first install the command line tool ffmpeg.
You can install it by using any one of these commands in the command line.
# on Ubuntu or Debian sudo apt update && sudo apt install ffmpeg
on Arch Linux
sudo pacman -S ffmpeg
on MacOS using Homebrew (brew.sh)
brew install ffmpeg
on Windows using Chocolatey (chocolatey.org)
choco install ffmpeg
on Windows using Scoop (scoop.sh)
scoop install ffmpeg
Install Whisper
From the command line, run the below command
pip install git+https://github.com/openai/whisper.git
This command will pull all the required Whisper code and python dependencies and install it on your computer.
Using OpenAI Whisper
From the command line
In order to convert an audio file into text, use the below command
whisper audio.wav --model medium
Replace audio.wav with your audio filename. The model chosen here is medium. A list of all models available is below section.
To transcribe multiple files, use this command
whisper audio.flac audio.mp3 audio.wav --model medium
The below command will transcribe a Japanese audio file.
whisper japanese.wav --language Japanese
replace the language with the language of your file.
In order to translate non-English audio to English, add the option –task translate to the command, like this
whisper japanese.wav --language Japanese --task translate
From inside a python script
Use the below code to use Whisper to transcribe audio
import whisper
model = whisper.load_model("base") result = model.transcribe("audio.mp3") print(result["text"])
The above code first imports whisper. It then loads the base model. then it uses the model to transcribe an aduio.mp3 file. then the resulting text is printed on the screen. You can replace the base model with an appropriate model from the below list.
Various OpenAI Whisper models
Whisper comes with various models. They vary depending upon
- how they perform in various languages,
- how much GPU VRAM they need to run, and
- speed
Size
Parameters
English-only model
Multilingual model
Required VRAM
Relative speed
tiny
39 M
tiny.en
tiny
~1 GB
~32x
base
74 M
base.en
base
~1 GB
~16x
small
244 M
small.en
small
~2 GB
~6x
medium
769 M
medium.en
medium
~5 GB
~2x
large
1550 M
N/A
large
~10 GB
1x
Use the appropriate model based on your need.
OpenAI Whisper language support
OpenAI performs best on English speech-to-text transcription. However, it does quite well for non-English languages, both for transcription and translation to English tasks. Here is an industry scoring for Whisper in various languages.
 Image Credit: OpenAI. Whisper Language support
Image Credit: OpenAI. Whisper Language support
Also, check out the hosted OpenAI Whisper API Guide.